Operating System Concepts - Chapter 10
Welcome back, I know I’m not actually really consistent in this series but I will try my best in the upcoming times. Wish me luck.
Anyway, in this chapter I discovered a lot of interesting stuff that I’m excited to share and summarize. So let’s dive in.
Virtual Memory
Virtual memory is a technique that allows the seperation of logical memory from physical memory (By physical memory I mean RAM, so not to get confused later). This technique facilitates the development process alot, as programmers don’t care about where their code gonna live eventually it’s the OS task to manage that. Additionally, virtual memory allows the execution of processes that are larger than the physical memory itself, by using secondary storage (like disks) as an extension to the physical memory (This accompaines with some other analgies that we shall discuss shortly).
Virtual address space of a process refers to the logical view of the memory and how the process stored the data in memory. Each process has its own virtual address space, which is divided into blocks called pages. The size of a page is typically between 512 bytes to 16 MB, depending on the architecture and hardware ig. The virtual address space of a process is similar to the following layout:
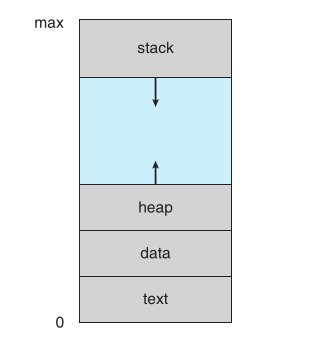
As you can see, the virtual address space has a large blank space, between the heap and the stack, this space is not mapped yet in the virtual memory, nor the physical memory. But as the data grows, the OS can map this space to physical memory as needed.
Virtual memory also enables page sharing between processes, like shared libraries in Linux or C. This means that if process A and process B both use the same library, the OS can map the same physical page to both processes’ virtual address spaces, which is a win win situation. Why that is possible ? because shared libs are typically read-only, so no process can modify the content of the pages they share (or can they? try to think in a design where processes can edit shared space safely). This can be also used during the fork() syscall, where the child not nessciarly needs a full copy of the parent’s memory space, instead both parent and child can share the same pages until one of them tries to modify a page (This is called copy-on-write, we will discuss it shortly).
Demand Paging
Now, when you play a game or run an application, do you need all the program or game logic to be loaded in the memory at once? Most likely no, there are some codes for corner cases and error handling that could be rarely be executed. So instead of loading the whole program into memory (which is not realistic think about loading Rainbow Six Siege entirely into RAM you gotta be giga rich for that). Alternatively, The OS can load only the pages you need to execute the program, and while you are playing, if you needed additional pages from the disk, the OS can load them on demand. This technique is called demand paging.
Demand paging requires the hardware support of a page table and a page fault mechanism. Consider you have a full logical memory of 4 pages A, B, C, D, this is your entire program. However, the OS only loads pages A and C into memory. Now, when the CPU tries to access page B, it will be mapped to nowhere in the physical memory, this will cause a page fault. page fault will make the OS intervene, and the logic will be as follows:
- The OS will check an internal table to see if page B is a valid page in the logical memory.
- If it is invalid, teriminate it. If it is valid, but not yet loaded in physical memory, we page it now to the physical memory.
- Checking if there is a free frame in physical memory, if yes, load page B into that frame. If no free frame, we need to evict a page from physical memory using a page replacement algorithm (we will discuss it as well).
- Update the page table to reflect the new mapping of page B to the physical frame.
- Restart the instruction that caused the page fault in order to execute normally as nothing happened.
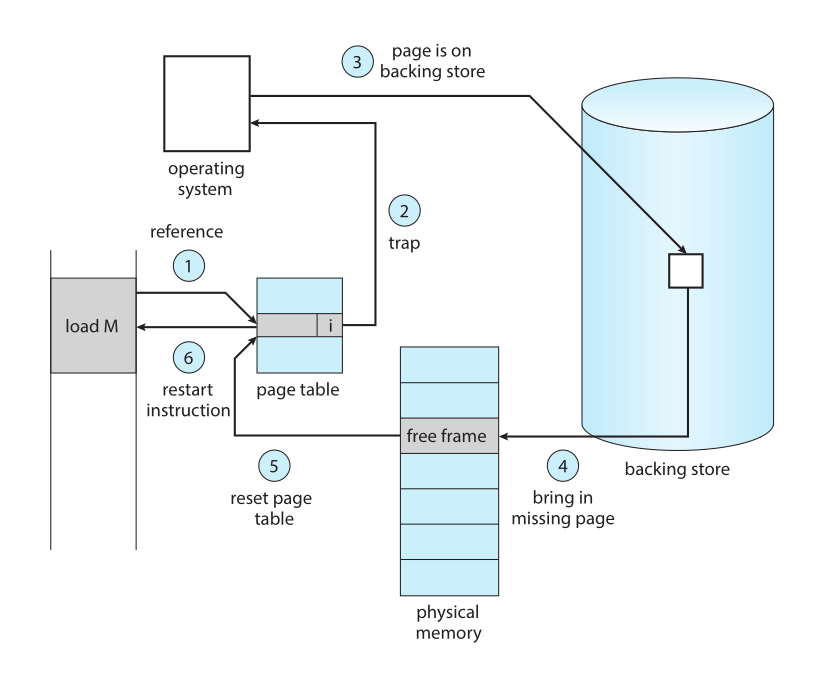
There is an extreme case of demand paging called pure demand paging, where no pages are loaded into memory at all when the process starts, and all pages are loaded on demand. This kinda sucks you know, because the first instruction will be a page fault for sure, the second might be as well, and you will spend a lot of time doing I/O while you could have loaded some pages in advance.
Let’s take an example to see how page faults are handled, consider the following ADD operation:
ADD C, A, BIn this instruction, the CPU tries to add A and B, and store the result in C. I already have loaded A and B, so I will add them normally, but C is not yet loaded. So when the CPU tries to store the result in C, it will cause a page fault. The OS will handle the page fault as discussed before, knowing that C is a valid page, it will get it and then restart this instruction, decoding it again and adding A and B again, this is few nanoseconds not a big deal.
It gets bad when you have multiple page faults in a row, like if A, B, and C were all not loaded. you will do this rolercoaster for each page fault of them. Even worse, what about instructions that are used to move data from source to destination, like:
MOV C, AWhere those two operands can overlap in memory, so restarting the instruction again after processing it partially will cause a mess.
OS designers always come with great solutions, so to solve this problem, the OS can use one solution to try to access the beginning and the end of the instruction, knowing that they are going to be sequenctially accessed, so if there was no page faults in the beginning and the end, the OS can assume that the middle part is safe to access as well without causing page faults. The other solution uses temporary registers to store the data overritten, if a page fault happens, the OS can restore the data from them before traping the process. (What about you ? Do you have better solutions ?).
Free-Frame List
Free frame list is simply a list of free frames in the physical memory that any process can request when it needs. it’s simply zero filled pages in the RAM that are not yet allocated to any process. Imagine it is a linked list (actually xv6 is doing it like that), where each node is a free frame, and the head of the list is the first free frame. When a process needs a frame, it takes the head of the list, and when it releases a frame, it adds it back to the head of the list.
Performance Calculation for Demand Paging
To calculate the effective access time (EAT) for a demand paging system, assuming p is the probability of a page fault. Ideally we want it to be zero, but ofc this is not going to be the case. let ma to be the memory access time (10-15 nanoseconds or whatever). Using the following formula, you can calculate it very easily:
effective time access = (1 - p) * ma + p * page fault timeWhere page fault time is ofc much larger than memory access time. using this formula, if you have a desired EAT, you can calculate the maximum acceptable page fault rate $p$ for your system.
There are some solutions to get better paging
- Copying an entire file image into swap space (as I/O to swap is faster than to file system) at process start up and then performing demand paging from there.
- Using demand paging normally, reading from file system, but writing to swap space instead.
Also their is a cool thing about binaries and executables, they don’t have to be written back at all, becuase they are read-only, so they can be simply overwritten when needed.
Now let’s talk about one of the coolest design patterns I have ever seen which is the copy-on-write.
Copy-On-Write (COW LMAO)
Copy-on-write (COW) is a technique, mostly used during the fork() syscall, where the parent and child processes share the same pages in memory until one of them tries to modify a page. At this point, this page is copied out separately for the parent (or child whoever has modified it), and the page table is updated to reflect the new mapping. This technique is very efficient, as it avoids the need to copy all the pages of the parent process to the child at the time of the fork(), which can for a very fertile process (you know what I’m saying).
Ofc this may need the support of the hardware to indicate that a page is modified after being shared, typically using a dirty bit in the page table entry or smth. There is a version of fork() called vfork() where the child use the page table of the parent directly, no COW here be careful tho, any modification will reflect on the parent, any stack modification will overwrite the parent’s. Sound useless right ? I thought that at first, but it’s mainly designed for calling exec() directly after vfork(), which replaces the entire memory space of the child. But still the difference between fork() and vfork() is not yet clear I feel you. vfork() just avoids any overhead of copying stuff of the parent, it will be thrown away anyway.
Page Replacement Algorithms
As we are allocating new frames, surely at some point we will run out of them. So we need to evict some to get others in. Removing randomly is provably bad idea, so we need some algorithms to tell us which page to remove based on some data we collect along the way. We will discuss quite a bunch of them, so buckle up.
First let’s get to know the main steps taking while having a page fault now:
- Find a free frame, if exists, use it, that’s it.
- No frames, call the replacer to get you a victim frame.
- Write the frame to disk if it is dirty.
- Read the required page into the newly freed frame.
- Update the page table to reflect the new mapping.
Now let’s discuss the FIFO
First-In-First-Out (FIFO) Replacement
FIFO is the simplest ever, put the frames used in a queue, when you need to evict one, just take the head of the queue, which is the oldest one. Simple as that. But ofc it comes with a price, as it may evict a page that will be needed in the next instruction for example. This queue should have a definit size which is the whole number of frames (theoritically speaking, but in practice ofc less for some reasons), so when the queue is full, adding a new frame will evict the head of the queue. This algorithms is vulnerable to Belady’s Anomaly, which means that increasing the number of frames may increase the number of page faults. Sound counter-intuitive right ? but it’s true.
See the following sequnce of page references:
1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5This the graph show the number of page faults for different number of frames using FIFO:
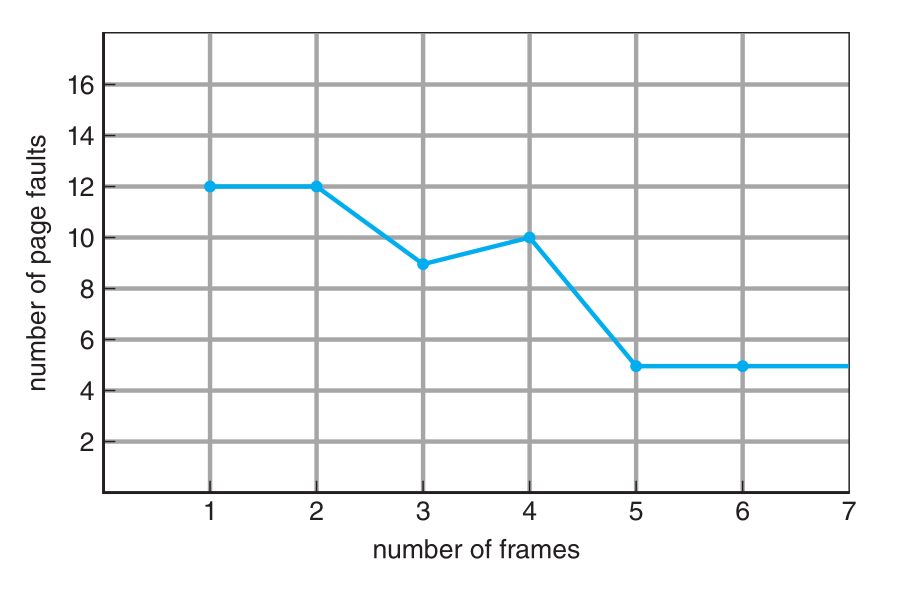
It should be always decreasing, but there is a spike at 4 frames, which is Belady’s Anomaly effect.
Optimal Page Replacement
This one is a little bit delisonary, as it is not implementable in practice, but it’s useful to know in case quantum computers become a real thing. it’s mainly saying evicting the page that will not be used for the longest period of time in the future. This is the most optimal as it can gets, but as you can see, we can’t know for sure which page will be used in the future, unless you have a crystal ball. Thre are some approximations could be made based on knowledge of the instructions, but still the overhead of calculation is not worth it.
Least Recently Used (LRU) Replacement
My favorite, LRU is based on the idea that pages that have been used recently are more likely to be used again, so evict the page that has not been used for the longest period of time. This can be implemented using two ways:
- Stack: well, it’s actually a linked list, where each time a page is accessed, it is moved to the top of the stack. When a page needs to be evicted, the page at the bottom of the stack is removed. This approach requires O(n) time for each access, as we need to search for the page in the stack (or maybe we can have some data structure to optimize this, some pointers directly to each page or whatever, but in OS they are trying to make it as simple as possible + O(n) is not a big deal grow up man).
- Counters: Each page has a counter of how many time it has been accessed, the least accessed will be kicked out. This approach requires O(1) time for each access, but it requires more space to store the counters. it also needs maintainance during schedualing and context switching to save and restore the counters.
And this can never suffer from Belady’s Anomaly, as increasing number of frames will for sure decrease the number of page faults. Test it if I’m wrong. Also for those interested you can read some of the chapter examples to know how the algorithm works by hand.
Those two algorithms tho, are not implementable in practice without hardware support, as we need to know when a page is accessed. So we can use some approximations. it can’t be an interrupt every page access happens, that would be a disaster bro.
There is a version of LRU called LRU-K, where K is the number of recent references to consider when making a replacement decision. For example, LRU-2 considers the two most recent references to each page. This can be done by keeping a 8-bit byte for each page or smth, for an LRU-8 I mean, and every specific interval of time (say every 100 milliseconds), we fire an interrupt to check the reference bits of each page, if the page is accessed mark the most significant bit of the byte to 1, then right shift the byte by 1. This way, the byte will contain a history of the page references over time, and we can use it to approximate LRU-K. For example, if the byte is 00010011, it means that the page was accessed recently (the last 3 bits are 1), but it’s less than a page with byte 11100011, which was accessed more frequently in the past. and if two have the same number of ones, like 00010011 and 00110010, we consider the larger byte value as more recently used. And for equal bytes, we can use FIFO to break the tie yk.
There is another version of LRU called the Second-Chance Algorithm, let’s discuss it.
Second-Chance Page Replacement
to be continued…